One-line exploratory front door for non-absorbing event studies
Source:R/nabs_event_study_simple.R
nabs_event_study_simple.Rd`nabs_event_study_simple()` is a deliberately opinionated convenience wrapper for the *first 30 seconds* of an analysis. You give it your data and the four column names that identify outcome / treatment / unit / time, and it tries to give you a sensible event-study figure with as little typing as possible.
Usage
nabs_event_study_simple(
data,
outcome,
treatment,
unit,
time,
methods = c("DCDH", "FE"),
include_twfe = TRUE,
lags = NULL,
leads = NULL,
controls = NULL,
verbose = TRUE,
full = FALSE,
max_units = 5000L,
sample_seed = 1L,
keep_fits = FALSE,
...
)Arguments
- data
A panel data frame, or a path to a Stata `.dta` file (which is read via [nabs_read_dta()] with default settings).
- outcome, treatment, unit, time
Character column names. The treatment column should be a 0/1 indicator (it is allowed to switch back to 0, i.e. non-absorbing).
- methods
Character vector of estimators to run. Any subset of `c("DCDH", "PanelMatch", "IFE", "FE", "MC")`. Default `c("DCDH", "FE")` – a cheap first look (DCDH plus two-way-FE imputation, no cross-validation). The heavier estimators (`PanelMatch`'s bootstrap and `IFE`/`MC`'s cross-validation) are opt-in: add them explicitly once the cheap pass looks reasonable, or call [nabs_event_study()] to tune them.
- include_twfe
Logical; if `TRUE` (default), also fit a naive TWFE reference series via [naive_twfe()] and overlay it in a neutral color.
- lags, leads
Integer pre- and post-period lengths. If `NULL` (default), reasonable values are auto-chosen from the panel: `leads` is set to roughly one third of the typical (median) post-treatment span across treated units (capped at 8), and `lags` to roughly one quarter of the typical (median) pre-treatment span (capped at 6). The median is used rather than the maximum so that a single unit with an unusually long history does not inflate the window. Override either explicitly to be sure of the window.
- controls
Optional character vector of covariate names; passed straight through to each estimator.
- verbose
Logical; if `TRUE` (default), print a brief progress message before each estimator runs.
- full
Logical; if `FALSE` (default) and the panel has more than `max_units` units, a random sample of `max_units` units is used so the first pass stays fast. Set `full = TRUE` to use every unit.
- max_units
Integer; the unit cap used when `full = FALSE` (default 5000).
- sample_seed
Integer seed for the first-pass subsample, so the quick look is reproducible. The caller's global RNG state is left untouched.
- keep_fits
Logical; if `FALSE` (default) the heavy native estimator objects are not retained in `$fits` (they can be gigabytes for `fect`). Set `TRUE` if you need them for diagnostics.
- ...
Forwarded to [nabs_event_plot()] (e.g. `xlim`, `ylim`, `palette`, `ylab`, `x_break_by`). Stata-style aliases are also accepted here and translated with an informative message: `df` (for `data`), `group` (for `unit`), `placebo` (for `lags`), and `effects` (for `leads`; note `leads = effects - 1`). See the "nonabsdid for Stata users" vignette.
Value
A list of class `"nabs_event_study_simple"` with elements:
- `plot`
A `ggplot` object; the overlay figure.
- `tidy`
A single combined `nabs_event_study_tbl` with all methods.
- `per_method`
Named list of per-method tidy tibbles.
- `fits`
Named list of native estimator objects.
- `twfe`
The TWFE reference (or `NULL`).
- `call`
The matched call.
Details
By default it runs **all three** heterogeneity-robust estimators (DCDH, PanelMatch, IFE) plus a naive TWFE reference, and returns a single overlay plot along with the tidy tibbles and raw fits. Use it to *see the picture quickly*; for a careful, publication-ready result, switch to [nabs_event_study()] and tune options per estimator.
If a particular estimator's package is not installed, that estimator is silently skipped with a message and the rest are still attempted. This is intentional: the goal of `_simple()` is to give you *something* to look at even if your environment isn't fully provisioned.
Errors from a single estimator (for instance, PanelMatch failing because there are too few clean controls in the lag window) are caught, reported as a warning, and the remaining estimators continue.
Examples
if (requireNamespace("DIDmultiplegtDYN", quietly = TRUE) &&
requireNamespace("polars", quietly = TRUE)) {
set.seed(1)
library(polars)
panel <- expand.grid(id = 1:60, t = 1:10)
panel$d <- with(panel, as.integer(
(id %% 4 == 1 & t %in% 4:7) |
(id %% 4 == 2 & t %in% 5:8) |
(id %% 4 == 3 & t %in% 6:9)
))
panel$y <- 0.2 * panel$t + 0.5 * panel$d + rnorm(nrow(panel))
res <- nabs_event_study_simple(
panel,
outcome = "y",
treatment = "d",
unit = "id",
time = "t",
methods = "DCDH",
include_twfe = FALSE,
lags = 2,
leads = 2,
verbose = FALSE
)
res$tidy
}
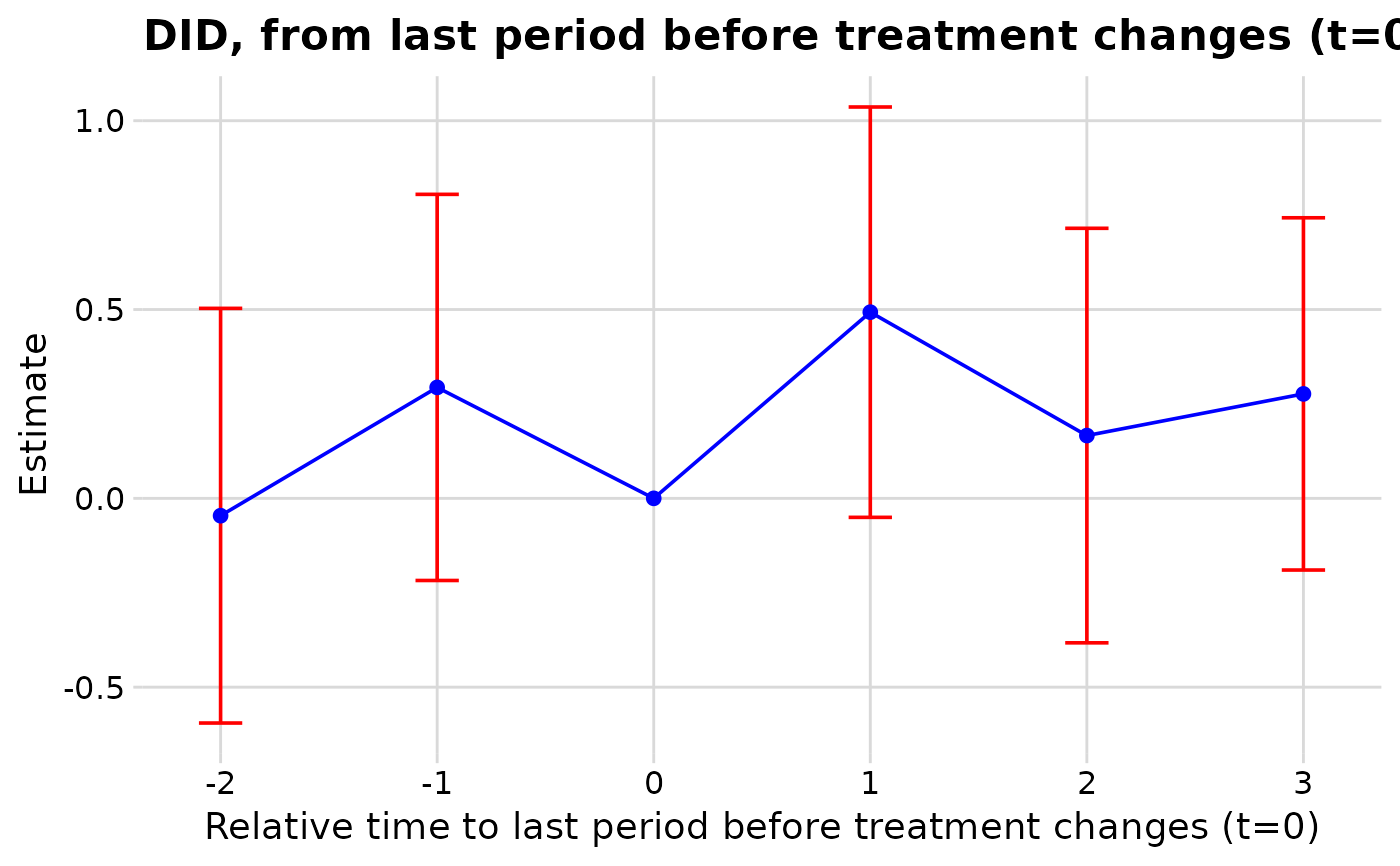 #> # <nabs_event_study_tbl>: 6 rows, methods: "DCDH"
#> # A tibble: 6 × 8
#> time estimate std.error conf.low conf.high window method outcome
#> <int> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr>
#> 1 -3 -0.0459 NA -0.595 0.503 pre DCDH y
#> 2 -2 0.294 NA -0.217 0.805 pre DCDH y
#> 3 -1 0 NA 0 0 pre DCDH y
#> 4 0 0.493 NA -0.0503 1.04 post DCDH y
#> 5 1 0.166 NA -0.383 0.715 post DCDH y
#> 6 2 0.277 NA -0.190 0.743 post DCDH y
#> # <nabs_event_study_tbl>: 6 rows, methods: "DCDH"
#> # A tibble: 6 × 8
#> time estimate std.error conf.low conf.high window method outcome
#> <int> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr>
#> 1 -3 -0.0459 NA -0.595 0.503 pre DCDH y
#> 2 -2 0.294 NA -0.217 0.805 pre DCDH y
#> 3 -1 0 NA 0 0 pre DCDH y
#> 4 0 0.493 NA -0.0503 1.04 post DCDH y
#> 5 1 0.166 NA -0.383 0.715 post DCDH y
#> 6 2 0.277 NA -0.190 0.743 post DCDH y